Introduction to Parallel Programming
Now that we have gained an understanding of how to write fast code in Julia, or more accurately - how to avoid writing slow performing code in Julia, we can move onto to trying to utilise modern hardware to accelerate our software.
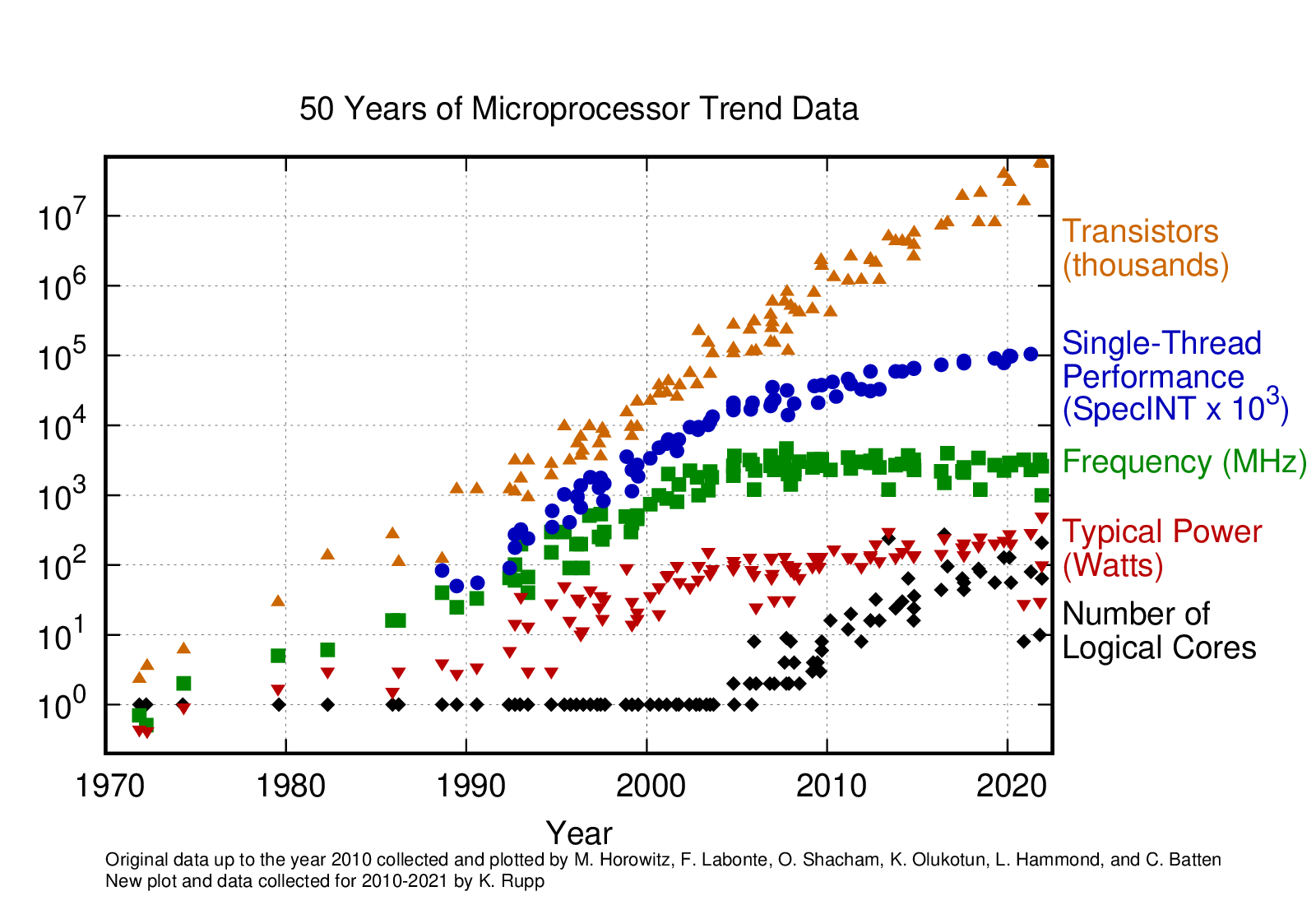
Over the past few decades, single-core performance has not been improving at the rate it once was. We can see this in the figure above, as it clearly shows this performance stagnating, along with clock speed frequency. Now, the way that manufacturers have sought to increase the performance of their chips, was simply to add more cores to a single CPU, you can see this trend beginning in the mid 00’s. While each core might only be 10% faster than the last generation, it may now have twice as many cores, and theoretically, able to at least double the performance, given the right task and software. Now, some manufacturers are able to fit 128 cores onto a single chip. Additionally, some motherboards are dual socket, which means they can fit two CPUs and have twice the number of cores available.
While in theory, one can increase the amount of computational power available, there are quite a few challenges:
- Some tasks are inherently sequential, and cannot be divided up amongst multiple cores and are limited to sequential processing. An example of this is in a Physics engine, where one has to work out the current state of the simulation before being able to calculate the next state. While the forces can often be calculated in parallel, each distinct step relies on the previous step and has to be done in sequence.
- Developers need to write the code in such a way that it can efficiently utilise multiple cores, while working across many different computers and architectures. This adds a lot of complexity to the code base and requires a much higher level of expertise, let alone the increased amount of testing required to ensure the software performs as expected. Many applications today under-utilise the hardware due to this increased burden on the developers.
- In order to parallelise the code correctly, the algorithms can be completely different, requiring huge amounts of developer time to rewrite and test these new algorithms. This process is fraught with bugs which make software less reliable. Reliability is often preferred over speed, and so parallelising code is often overlooked.
- If done incorrectly, parallelised code can often be slower than the serial alternative. It is important to know when to parallelise and when not to.
This chapter will aim at exploring these challenges and give you the theoretical tools to understand the framework of parallelisation.
Summary
Throughout this chapter, we have looked at the theoretical basis of parallel computing. Many of the examples shown use the multithreading paradigm, however, we will also have an in-depth look at multiprocessing and even GPU parallelism in later chapters.