Modern GPU Hardware

Modern GPUs are not limited to graphical applications, such as gaming and 3D rendering, but can also be very effective at accelerating scientific simulations. A modern user with access to a consumer level GPU now has access to a comparable level of compute as supercomputing clusters from the early 2000s (as measured by peak FLOPS1).
A GPU is a type of co-processor which connects to the CPU via the motherboard. This connection is usually through a PCIe bus2 and often requires a separate power connection to run. The GPU has its own on-board memory and contains many processor cores, typically on the order of 1000s.
Many modern high performance clusters now include many GPUs. Take the Sulis HPC based at the University of Warwick as an example. Sulis has 90 NVIDIA A100 Tensor Core GPUs, which can cost upwards of £20,000 each. Let’s take a closer look at the hardware specifications of one of these cards:

- The A100 supports the PCIe Gen4 standard which is capable of a maximum of 64 GB/s memory bandwidth between the GPU and the CPU.
- The A100 has 40 GB of HBM23.
- The A100 has a theoretical maximum Single-Precision Performance of 19.5 TFLOPs4. Single-Precision (FP32) refers to 32 bit floating point numbers, with 8 bits to represent the exponent (the range) and 23 bits for the mantissa (the precision).
- This card also supports using the Tensor Float (TF32) standard which uses the same number of bits as FP32 for the exponent, while only using 10 bits for the mantissa, like FP16. The TF32 precision allows for reaching a maximum of 156 TFLOPs of performance.
If we assume that each CPU thread is capable of performing a single floating point operation per clock cycle and runs at 4 GHz, and a CPU has 64 cores and 128 threads, we can estimate that this machine is roughly capable of 0.512 TFLOPs of performance. While this calculation is not completely accurate, it is clearly at least an order of magnitude slower than our GPU example.
In the figure below, we can see a rough depiction of the structure of the A100 chip. This contains many thousands of individual processors along with separate on-device memory. Processors are grouped into SMs (Simultaneous Multiprocessors), which are also grouped into blocks. There are multiple separate memory chips with their own memory controllers to facilitate both a high capacity of memory and a high bandwidth.
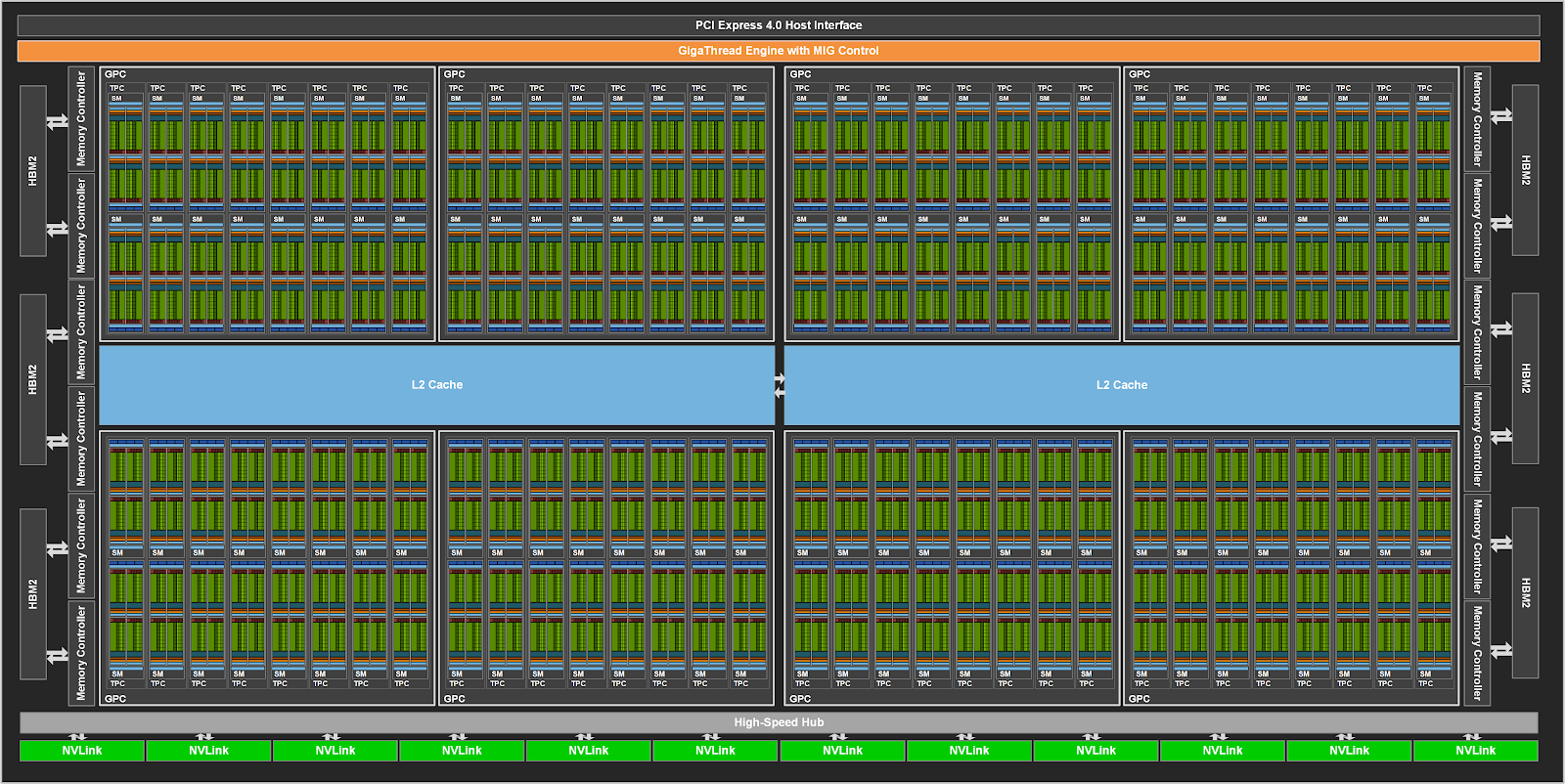
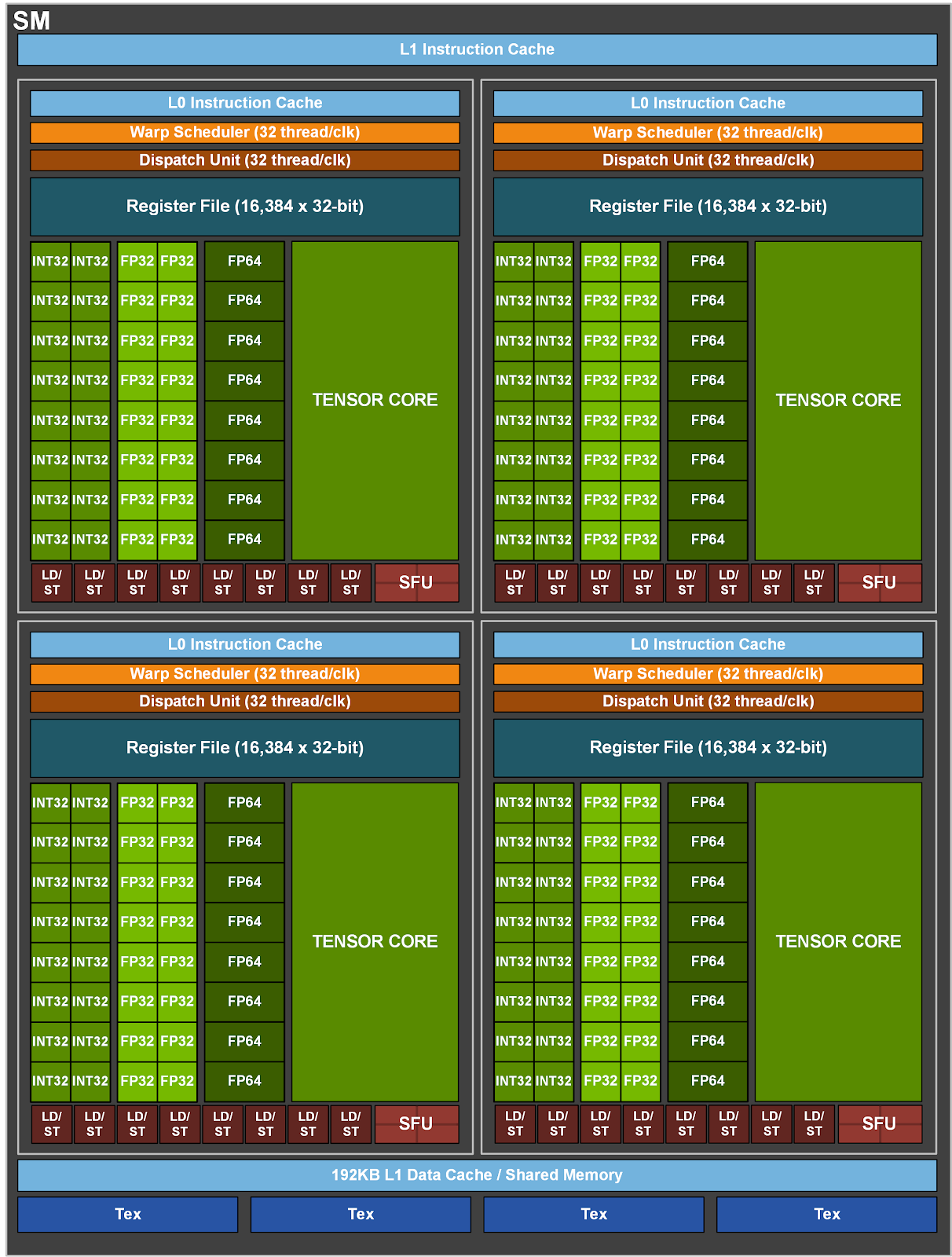
The diagram above can be zoomed in to show a single SM unit, as seen in the figure below. This SM contains its own lower level caches, independent of other SMs. Additionally, each unit has its own set of registers allowing them to execute independently. The processing units (in green), are optimised for high throughput arithmetic, and are not as capable as a generic CPU core. However, the purpose of these cores is to maximise throughput, not generality or latency.
Footnotes
- Floating-Point Operations Per Second.↩
- A PCIe (Peripheral Component Interconnect Express) bus is a standard, high-speed, interface for connecting external hardware to a motherboard↩
- High Bandwidth Memory, a standard for high performance local memory. This memory is often much faster and higher bandwidth than the RAM typically used in a modern computer.↩
- Teraflops - floating-point operations per second.↩