Speed of Operations
This section is based off information from ithare.com, whose article is very well written and should be viewed.
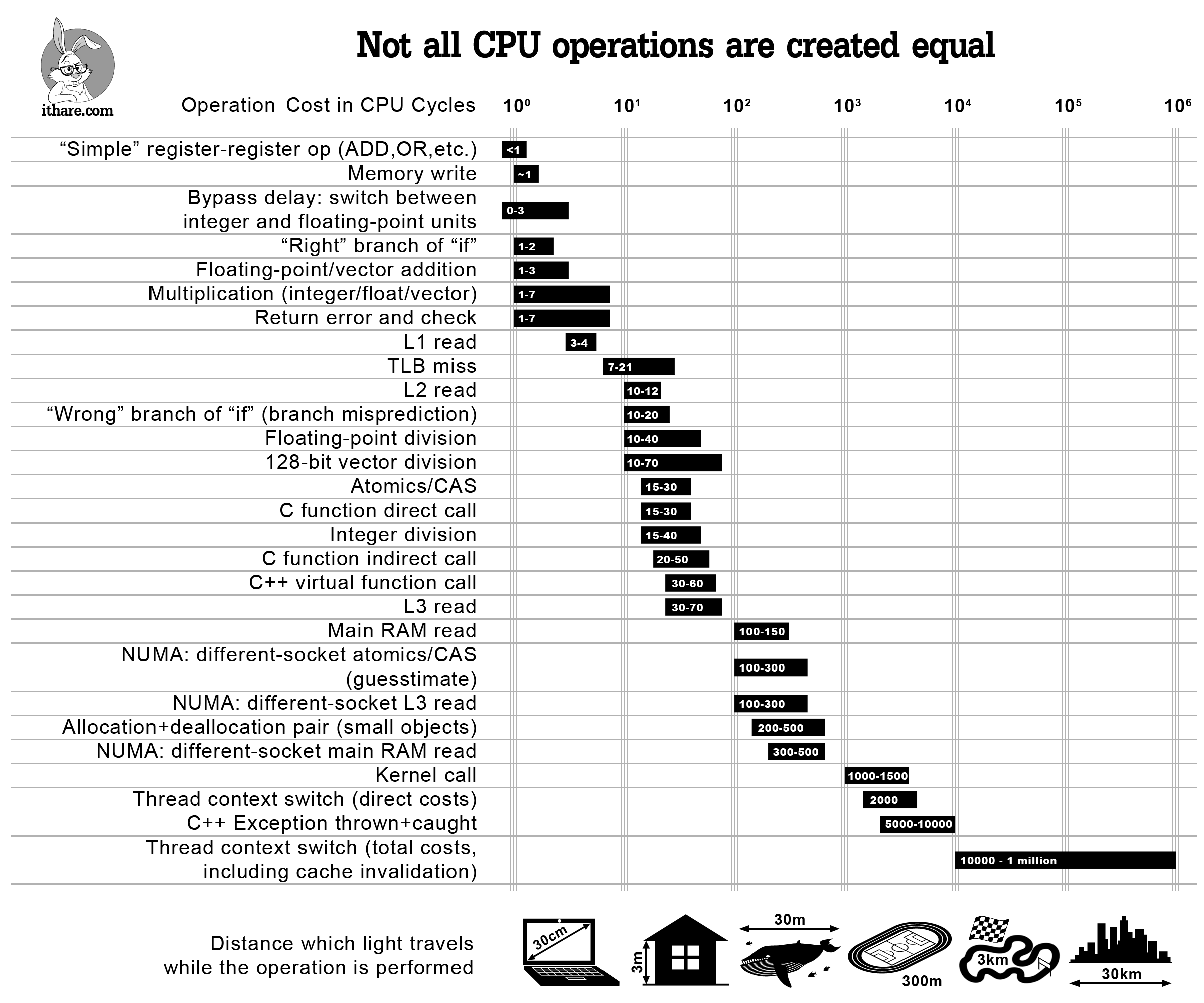
Taking a look at this graph, we can see that the basic operations, such as addition, multiplication and even memory writes are very fast. A lot of the details of this graph are too complex to see, but one heuristic to see is the different speeds of cache misses and allocation. One can see that allocation tends to be orders of magnitude slower than simple cache read and writes, or simple numeric calculations. Additionally, one can see that branching operations (if statements) can be very costly when mispredicted.
Modern CPUs often use branch prediction to start execution one of the branches of an if statement while the statement is checked. If the CPU gets the prediction wrong, then it has to backtrack which costs many cycles. This is one of the reason you see many people opting for “branchless” programming styles, where control loops are kept to a minimum. This usually involves using boolean numerics to set a value to zero if something is false and one otherwise and then summing both results together. Branchless programming can have significant performance improvements if done correctly.
Let’s look at an example of branchless programming:
function branched_absolute(x)
if x < 0
return -x
else
return x
end
end
function branchless_absolute(x)
# Convert boolean to 0 or 1, then use arithmetic
mask = x < 0
return x * (1 - 2 * mask)
end
# Test with some data
x = rand(-100:100, 1000);
import BenchmarkTools: @benchmark, @btime, @belapsed
display(@benchmark map(branched_absolute, $x))BenchmarkTools.Trial: 10000 samples with 287 evaluations per sample.
Range (min … max): 267.010 ns … 4.399 μs ┊ GC (min … max): 0.00% … 62.10%
Time (median): 291.105 ns ┊ GC (median): 0.00%
Time (mean ± σ): 443.760 ns ± 343.278 ns ┊ GC (mean ± σ): 16.31% ± 18.91%
██▃▁▂ ▁▁▁▁▁▁ ▁ ▁
██████▇▆▅▆▆▇▇▇▇▆▅▅▆▆▆▇████████████████▇▇▇▇▇▇█▇▇▇▇▆███▆▇▆▆▆▅▅▅ █
267 ns Histogram: log(frequency) by time 1.67 μs <
Memory estimate: 7.88 KiB, allocs estimate: 3.display(@benchmark map(branchless_absolute, $x))BenchmarkTools.Trial: 10000 samples with 276 evaluations per sample.
Range (min … max): 285.493 ns … 2.899 μs ┊ GC (min … max): 0.00% … 39.49%
Time (median): 321.130 ns ┊ GC (median): 0.00%
Time (mean ± σ): 414.569 ns ± 241.523 ns ┊ GC (mean ± σ): 21.40% ± 22.59%
▇█▄
████▆▄▃▂▂▂▂▂▂▂▂▂▂▂▂▂▁▁▂▂▁▁▂▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▂▂▃▃▄▄▃▃▂▂▂▂▂▂ ▃
285 ns Histogram: frequency by time 1.08 μs <
Memory estimate: 7.88 KiB, allocs estimate: 3.In many cases, the compiler is smart enough to optimize branches automatically, but understanding these principles can help in performance-critical code.