Hardware
Earlier in this chapter, we learnt about the von-Neumann architecture which offers a simplified model for how modern computers operate. For this section, we will connect these earlier ideas with their counterparts in a real computer. Understanding modern hardware is absolutely key to writing high-performance software.

Central Processing Unit (CPU)
The CPU is the central part of any computer. It acts as the “brain” of the computer and as the name suggests, handles all the processing of the computer. This device usually sits near the centre of the board. In Figure 1, the CPU is housed in socket A. CPUs often come in different form factors and are designed to fit in different sockets, however, there is usually overlap between the same products that a manufacturer produces.
Multicore Chips
Modern CPUs are often designed to be to processes multiple tasks at the same time. For example, when you use your computer, there are usually multiple programs all running at the same time, such as browsing the web, writing a document and listening to music. Older, single core CPUs were able to handle multiple programs at the same time as they would allow each process to run for a while amount of time, switching tasks every few micro seconds. To the user, it appears as if each program is running at the same time, when in fact, only one program is running at any given time. This is called concurrency, and it is the illusion of parallelism. However, modern CPUs have truly parallel capabilities since the majority of modern CPUs actually contain multiple processing cores. If your CPU has 4 cores, it is theoretically possible to speed up some workloads by a factor of 4; often, it is not possible to achieve this level of speed-up with parallelism, but we will discuss this later on in the course.
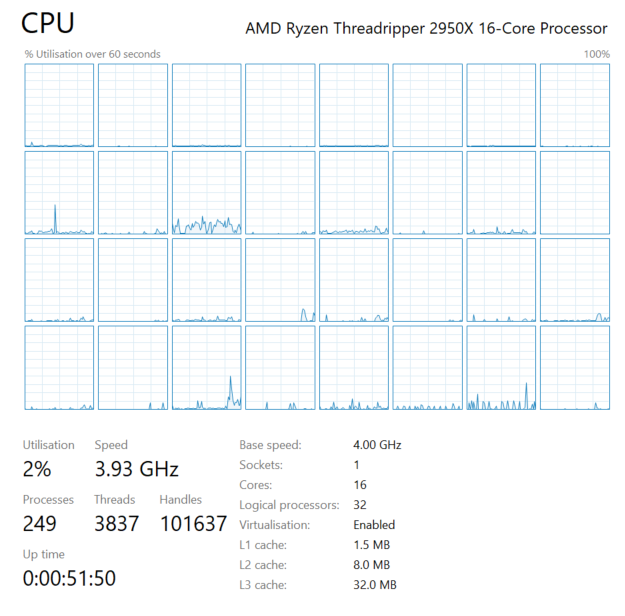
If you look at Figure 2, you can see that this processor has 16 cores. This means the entire CPU is made up of 16 processing units, that can individually work on a task. Task manager shows 32 “logical processors” on the computer, which may be confusing at first. This is quite common for many higher-end chips. This is known as Simultaneous Multithreading (SMT) or Hyperthreading1. SMT is a special type of technology which increases the throughput of each individual core, allowing an increased amount of parallel processing. Not all workloads can benefit from this increased performance, but highly parallelised (and task diverse) workloads may see increased performance on these chips when using all the logical processors, and not just each physical core.
Instruction-level Parallelism
Some modern CPUs have built into them the ability to manipulate multiple pieces of data at the same time, provided they are in a suitable format. Take the problem of adding two vectors together.
Notice that there are 4 add operations here, but they are all independent of one another. Modern CPUs tend to have advanced instructions for doing this operation all at once. It works by taking the 4 values from the first and second vector all at the same time, and putting them in a special arithmetic unit on the CPU which can add numbers in parallel. Note that the CPU must have special, wider registers, capable of storing multiple values in that same buffer. There are many implementations in hardware, but the most common ones are AVX2 and SSE3. These specialised instructions are known as SIMD (Single Instruction Multiple Data).
SIMD instructions can speed up common vector and matrix operations by a large factor. Let’s look at a straightforward example in Julia:
function custom_sum(numbers)
total = zero(eltype(numbers))
@inbounds for x in numbers
total += x
end
return total
end
function custom_sum_simd(numbers)
total = zero(eltype(numbers))
@inbounds @simd for x in numbers
total += x
end
return total
endWhile we haven’t covered Julia specific syntax here, you should know that Julia makes use of macros such as @inbounds and @simd here, which allows the compiler to rewrite the code inside. Macros are a way for the programmer to write code that writes code. The @inbounds macro simply tells the compiler to ignore bounds checking (making sure that you index into an array correctly), while the @simd macro gives us an easy way to tell the compiler to use SIMD instructions in our sum. In this example, we can add together say 4 numbers from our array at a time, instead of only adding one at a time.
The code below is a small example which compares the runtime of the above two implementations. The first result will show the summation without using the SIMD hardware-level optimisations and the second will show the runtime with these optimisations “turned on”:
using BenchmarkTools
numbers = rand(Float32, 256);
println("For Loop (non-SIMD)")
@btime custom_sum($numbers)
println("For Loop (SIMD)")
@btime custom_sum_simd($numbers)For Loop (non-SIMD)
68.954 ns (0 allocations: 0 bytes)
For Loop (SIMD)
4.374 ns (0 allocations: 0 bytes)We can see that the SIMD version has a significant speed-up (around x speedup), but requires very little effort on our part. As floating point addition is not associate, the result from these functions will be different as we have changed the order of the summation. The amount of speed-up you will experience depends entirely on the algorithm and the CPU that you run this example on. If you are running on an older chip that does not have vector instructions, the SIMD code may not perform faster than the non-SIMD code.
We could inspect the code produced, using the @code_llvm macro, however, only one part of the output is informative for this discussion. Some of the instructions are typed with a < 8 x float > description. These instructions are showing us that 8 32-bit floating point numbers are being loaded and processed in a single CPU instruction. There are some other optimisations as well, such as using the fast math versions of the addition, but overall, the majority of the speed-up comes from using the special instructions on the modern CPU. The hardware on the processor allows for processing 256 bits of information at the same time4. Since we used 32-bit numbers, we were able to perform 8 simultaneous additions. If we were to use double precision floating point numbers (64 bits each) we could only fit 4 numbers into the SIMD register.
It should be noted that not all operations are suitable for a SIMD speed-up and this optimisation should only be considered for performance critical code.
Cache
In order to do any amount of processing, the CPU needs access to memory, not only for the data to operate on, but the instructions to use for processing. The bulk of the active memory storage that a CPU relies on is not stored in the CPU itself, but in an external device (RAM). Accessing memory from outside the chip takes a lot of time, which the CPU could have been using for data processing. This is why modern CPUs usually have a small amount of very fast memory called cache, which lives on the CPU alongside the processing cores. Accessing data from cache is orders of magnitude faster than requesting from main memory.
There are multiple levels of cache, referred to as L1, L2 and L3 cache. The higher the number, the slower the cache is to access. Each CPU core has its own L1 cache, and this is the fastest cache the CPU can access - the only way to access memory faster is to have that memory already inside the core’s registers. The core can copy data out of this L1 cache and into its registers within a few CPU cycles. The L1 cache is the smallest of the CPU caches. One level up, we have the L2 cache, which is shared by multiple cores. This cache is often much larger and takes only slightly more time to access if the requested data is not in the L1 cache. L3 cache is the largest and slowest of the cache levels and is the last cache to check before being forced to request the required data from main memory. If your program requests from main memory instead of finding the information in the cache, this is often called a cache miss, and is a topic of great importance in optimisation. If you can redesign your code to have a much lower rate of cache misses, it will likely run many times faster. While a programmer does not have direct control over how memory is placed into /purged from the cache, there are optimisation techniques that reduce the chances of cache misses. These techniques will be covered in the Optimisation chapter.
Motherboard
The motherboard acts as the glue connecting all computer components, facilitating both power delivery and data transfer. It provides external connections via ports and internal communication channels, enabling the CPU, RAM, storage, and peripherals to work together.
Random Access Memory (RAM)
RAM serves as the computer’s working memory, offering fast storage for active tasks. Storage in RAM is volatile, which means that the data stored inside is lost when the component is powered off. When booting up your computer, any memory that is needed must be copied from storage into RAM. RAM is much slower to access than CPU cache, but is much faster to access than physical storage. Modern RAM is often in the s of gigabytes (GBs) on modern systems.
Storage
Solid State Drives (SSDs)
SSDs offer fast, power-efficient storage with no moving parts, making them much faster than traditional HDDs. However, their cost per GB is higher, so they are often used alongside higher capacity HDDs for speed-critical applications.
Hard Disk Drives (HDDs)
HDDs are traditional storage devices with spinning magnetic disks. They offer high capacities at lower costs but are much slower than SSDs. CPU instructions often handle communication with HDDs asynchronously due to their slow speeds, which can create bottlenecks in poorly optimized systems.
Network I/O
Modern computers rely on network interfaces for internet and local communication, supporting protocols like Ethernet and Wi-Fi. These interfaces connect systems and peripherals, enabling data exchange and distributed computing.
Peripherals
Peripherals include devices like keyboards, mice, printers, and external storage. They enhance a computer’s functionality and are typically connected via USB, Bluetooth, or other standard interfaces.
Graphics Processing Unit (GPU)
GPUs are specialised coprocessors optimized for parallel tasks, such as rendering images or processing large datasets. They excel in SIMD (Single Instruction Multiple Data) workflows and have thousands of cores for simultaneous operations. GPUs are increasingly used for general-purpose tasks (GPGPU), leveraging their ability to process large-scale, parallel workloads efficiently. High-end GPUs are also essential to tackle data processing when training large scale AI models, a task that would not be possible without the parallelism that GPUs can offer. Later on in the course we will discuss GPUs in more depth and discuss how we can write code to utilise the GPU.
Memory Access Performance Across Devices
To understand the relative speeds of accessing different levels of memory, the following table provides typical values for the time taken (in CPU cycles) to access data from various memory levels and storage. These values are approximate and can vary depending on the architecture and specific hardware configuration, but they illustrate the significant performance differences.
| Memory/Storage | Typical Access Time (CPU Cycles) | Approximate Size |
|---|---|---|
| Registers | 1 | A few KB per core |
| L1 Cache | 3–5 | 32–128 KB per core |
| L2 Cache | 10–20 | 256 KB–2 MB per core |
| L3 Cache | 40–70 | 2–64 MB shared |
| RAM | 100–300 | 8–64 GB |
| SSD (NVMe) | ~100,000 | 256 GB–2 TB |
| SSD (SATA) | ~500,000 | 256 GB–4 TB |
| HDD | ~5,000,000 | 1–16 TB |
Key Observations:
- Registers: Fastest memory as it’s located directly in the CPU core and has almost no latency. Used for immediate processing.
- Cache: Accessing L1, L2, or L3 cache is faster than RAM but comes with trade-offs in size and latency. Smaller, faster caches are closer to the core.
- RAM: Offers larger storage for active processes but introduces a noticeable delay compared to cache.
- Storage: Accessing data from SSDs or HDDs is significantly slower, making them unsuitable for tasks requiring rapid memory access. SSDs are much faster than HDDs but still orders of magnitude slower than RAM.
- Bottlenecks: Programs frequently accessing storage can experience significant slowdowns unless proper caching or asynchronous I/O techniques are implemented.
This table highlights the critical importance of designing software to take advantage of faster memory levels whenever possible, minimising slower accesses to RAM or storage.
Footnotes
- The name when Simultaneous Multithreading (SMT) is included in Intel chips.↩
- https://en.wikipedia.org/wiki/Advanced_Vector_Extensions↩
- https://en.wikipedia.org/wiki/Streaming_SIMD_Extensions↩
- Many modern CPUs, such as Apple’s M1 processor, supports
AVX-512which allows processing on twice the number of bits as my machine. This allows for huge acceleration in many computationally intensive workloads.↩